

Related Chinese Code
- CNS11643 Chinese Standard Interchange Code
- BIG-5 Code
- BIG-5E Code
- zh_HK.hkbig5
- EUC Code
- CCCII Code
- ISO10646 and UNICODE Chinese Ideographs Character Set
- GB2312
- GBK
- The telecom code
CNS11643 National Chinese Standard Interchange Code
1. History
In September 1980, the Science and Technology Information Center (STIC) of Executive Yuan gathered local encoding specialists and academics to attend a conference in Shi-Tou. The preliminary encoding principles were determined and reported to the Executive Yuan for assessment as the Encoding Principles of National Chinese Information Standard Interchange Code. On September 2, 1981, the Executive Yuan sent an official memorandum to the STIC requesting the Center to invite the Ministry of Education (MOE), the Bureau of Standards and Metrology and Inspection (NBSMI) and the Electronic Data Processing Center Directorate, General of Budget, Accounting and Statistics, Executive Yuan (EDPC) to form a project working team and aggressively pursue encoding of Chinese characters. In July 1982, a single set of frequently used glyphs was encoded but the number of characters collected was inadequate. On May 9, 1983, the National Information and Communication Initiative (NICI) of Executive Yuan once again confirmed and set the encoding methodology and formed an encoding technical working group on May 12. The group aimed at discussing and studying the finer rules of the existing encoding principles. At the end of October, "Chinese Ideographic Standard Code for Information Interchange" (CISCII) was completed and it was resolved to trial the code for two years. Upon expiration of the trial period, the STIC and the EDPC invited various concerned organizations and enterprises to form a technical team. Subsequent to the team's review on trial results and amendments made to the encoding standards, in March 1986, the code was formally assessed and announced for implementation by the Executive Yuan. In August 1986, the code was announced to be the National Standard Code by the NBSI and was numbered CNS11643. In 1992, in response to requirements of various users, the code was extended from containing 2 character planes (13,051 glyphs) to 7 character planes (48,027 glyphs). In May, it was renamed the "Chinese Standard Interchange Code".
2. Intended Areas of Application
This standard is applicable to the processing of Chinese language information.
3. Encoding Considerations
(1) Restricted to character sets included in the four tables of standard characters announced by the MOE.
(2) Based on the frequency and the extent of application, glyphs are coded in each character plane to suit users of all levels.
(3) In compliance with "CNS5205 Information processing: 7-Bit Coded Character Set For Information Interchange" used for international information transmission & the standards of "CNS7654 Information processing: ISO 7-bit and 8-bit coded character sets - Code extension techniques".
(4) Include frequently used foreign language alphabets and glyphs used by industries, businesses and educational institutions.
4. Principles of Structuring Character Sets
(1) "Chinese Standard Interchange Code" provides 16 character planes. Each plane is divided into 94 rows and each row has 94 columns. Altogether, a total number of 8,836 glyphs can be accommodated in each plane. Character planes 1 to 11 are for standard Chinese characters while character planes 12 to 16 are user-defined areas, allowing users to define glyphs that are yet to be collected in the standard areas.
(2) The character set in each character plane is generally coded in the order of usage frequency. Character plane one is mainly for frequently used characters. Character plane two is for less frequently used characters. Character plane three is for rarely used characters and frequently used Chinese character variants. Character plane four is mainly used for Chinese ideographs of ISO DIS 10646 2nd edition, characters used in respective organization, Information Technology enterprises and the Residency System. Character plane five is for rarely used characters and character plane six and seven are mainly for Chinese character variants. Ideographs defined in character planes one and two were announced national standards on August 4, 1986.
5. Principles of structuring character codes
(1) Characters and fonts were selected based on the "Table of Standard Chinese Characters" published by the MOE. Description : There are mainly two hassles associated with the use of Chinese characters. One is that there are a large number of characters and the other is that the number of Chinese character variants is increasing. Currently, the total number of Chinese characters is large but in fact, those frequently used by people are around 5,000 characters only. New words continue to increase, thus making the processing of Chinese language information a hassle. The Table of Standard Character Sets published by the MOE is the work of many years in terms of collection, assessment, analysis and selection. It is an unbiased and objective source of ideographs currently in use and it suits the requirements of general users.
(2) Each Chinese character is represented by a two-byte code, which is represented by hexadecimal characters and numbers. Description : The use of a 2-byte encoding unit will increase processing efficiency and the speed of information transmission also becomes faster. These features meet the requirements of general data processing. Hexadecimal encoding is used as data processors are accustomed to this numbering method and it is the simplest way to represent a 2-byte unit.
(3) Comply with the standards of Information Interchange CNS 5205 and CNS 7654. Description : This encoding meets the requirements of the standards of information interchange CNS5205 and CNS7654. All control codes are avoided, which are "00" to "20" and "7F" of the code set. A 7-bit code set has 94 code positions and a 2-byte code allows coding for 8,836 characters, to form one character plane.
(4) Characters are defined in each character plane in the order of usage frequency. Description : At the time of transmitting information, if the characters to be transmitted appeared in different character planes, the control codes used to switch character planes must be sent out first. In order to increase transmission efficiency, words that commonly appear together are defined in the same character plane to reduce the number of times having to switch between character planes.
(5) Encoding in the order of Total Stroke Count and Radicals. Description : Each character plane is coded in the order of total stroke count, then radicals and lastly, stroke order. Users are only required to input the actual total stroke count of the character to find out the national standard code.
6. Description of Character Sets
(1) Standard Areas Plane One : In order to reduce the number of times required to convert character planes, most frequently used symbols, alphabets and radicals of Chinese characters are coded in character plane one. Coded characters and code areas are as follows: 1. Symbol Area The encoding area for symbols is planned at address 2121 to 427E of character plane one. The area comprises a total of 3,102 code positions. Currently, the 684 temporarily coded symbols are listed below : (1) 1 x tab (2) 28 x punctuation marks (3) 89 x brackets and tabulation symbols (4) 34 x general symbols (5) 51 x academic symbols (6) 31 x unit symbols (7) 42 numerical symbols including 10 Arabic numerals, 20 Roman numerals and 12 Chinese numerals (8) 100 foreign alphabets including 26 Capital English Alphabets, 26 Small English Alphabets, 24 Capital Greek Alphabets and 24 small Greek Alphabets. (9) 42 Chinese Phonetic Alphabets (10) 20 numerical order symbols (11) 213 Chinese character radicals (12) 33 control code symbols 2. Chinese Character Area Character Plane One : Coding interval from 4421 to 7D4B is encoded with 5,401 Chinese characters. Other than sourcing the 4,808 characters from the "Table of frequently used standard Chinese characters" published by the MOE, 587 characters and 6 variants frequently used in High School and Primary School textbooks are also coded. Character Plane Two : Coding interval from 2121 to 7244 is encoded with 7,650 Chinese characters. The character set includes 6,330 characters sourced from the "Table of less frequently used standard Chinese characters" published by the MOE and 1,320 more frequently used characters sourced from the MOE's "Table of rarely used standard Chinese characters" Character Plane Three : Coding interval from 2121 to 6246 is encoded with 6,148 Chinese characters. The character set is sourced from the first section of user-defined character plane 14, which was temporarily coded by the EDPC, Executive Yuan in June 1988. Character Plane Four : Coding interval from 2121 to 6E5C is encoded with 7,298 Chinese characters. The character set includes (1) 171 characters from the last section of user-defined character plane 14, which was temporarily coded by the EDPC, Executive Yuan in June 1988; (2) 7127 characters used in the Residency system and other organizations, ISO 10646 Chinese Ideographs Character Set, version 2 and frequently used characters in Information Technology enterprises. Character Plane Five : Coding interval from 2121 to 7C51 is encoded with 8,603 Chinese characters. The character set is sourced from the "Table of rarely used characters" published by the MOE, which have not been included in the previous four character planes. Character Plane Six : Coding interval from 2121 to 647A is encoded with 6,388 Chinese characters. The character set includes characters that have not been included in the previous five character planes and the Chinese character variants published by the MOE which are under (include) 14 strokes. Character Plane Seven : The coding interval from 2121 to 6655 is encoded with 6,539 Chinese Characters. The character set includes characters that have not been included in the previous six character planes and the Chinese character variants published by MOE which are under (include) 15 strokes.
(2) User-defined Areas To cater for different types of Chinese information processing, CNS11643 has reserved character plane 12 to 15 for user-defined characters. Chinese characters or symbols that have yet to be classified as national standard characters are coded in this area based on user requirements. p to 48,027 Chinese characters are encoded in the amended and extended version of CN11643. The code has covered characters as defined in the four "Table of Standard Chinese Characters" namely in the categories of frequently used, less frequently used, rarely used and Chinese character variants. However, since the implementation of the on-line computerized Residency Information System, the characters used to construct the national population database have exceeded the national standard characters by some 30,000 characters used for names. To enable data transmission and interchange for this type of character codes, the EDPC, Executive Yuan temporarily defined the interchange codes in user-defined areas: Character Plane 15: Coding interval from 2121 to 6D39 is encoded with 6,831 Chinese characters. Ideographs are sourced from the 15th character plane of the Residency Information System. EUC codes are used in the Residency Information System and the encoding principles of EUC codes are identical to those of CNS11643. For easier understanding, existing ideographs and definitions are used. However, amongst the 7,167 characters defined in character plane 15 of the Residency Information System, there are 2 self-repeating characters and 336 repeated characters that were already included in the first 7 CNS character planes. To avoid the situation of "one word, two codes", repeated parts are deleted to save the Household Registration and Military Service departments from having to repetitively convert codes; the spaces originally occupied by repeated characters are left blank after deletion.
7. Application of CNS11643
(1) Designation of Character plane In accordance with the regulations in Chapter 5.3.9 of CNS654 (July 15, 1989 edition), Chinese character codes can be placed in Multiple Byte Graphic Repertoire and designated to character set G1 by 4-byte escape order codes of ESC 2/4 2/9 F or designated to character set G3 by ESC 2/4 2/11 F. F can be used to designate the corresponding character planes from 1 to 16 by 3/0 - 3/15. As for English character sets, they can be designated to character plane G0 via ESC 2/8 F under the 7-byte environment. Currently, ending characters of CNS11643 character planes 1 to 7 are officially registered by the International Organization for Standardization (ISO) as 4/7 to 4/13 and can also be used in character set designation. Existing ending characters of CNS11643 character planes and ISO ending characters are cross-referred below:
| CNS Character Plane | CNS Ending Character | ISO Ending Character |
|---|---|---|
| Character Plane 1 | 30 | 47 |
| Character Plane 2 | 31 | 48 |
| Character Plane 3 | 32 | 49 |
| Character Plane 4 | 33 | 4A |
| Character Plane 5 | 34 | 4B |
| Character Plane 6 | 35 | 4C |
| Character Plane 7 | 36 | 4D |
(2) Character Plane Switching 1. Use G0 character plane by SI, Lock method. 2. Use G1 character plane by SO, Lock method. 3. Use G2 character plane by LS2, Lock method. 4. Use G3 character plane by LS3, Lock method. 5. Use G2 character plane by SS2, Non-lock method. 6. Use G3 character plane by SS3, Non-lock-in method. For convenience, when the terminal facilities are turned on, the three character sets G0, G1, G2 can be set as ASCII, character plane one and character plane two respectively, and character set G3 can be set as other frequently used character plane. *Note: Please refer to CNS7654 for further user details of the above control codes.
8. Promoting the application of CNS11643
The CNS11643 coding system complies with regulations of national standards. The Bureau of Standards, Metrology and Inspection, Ministry of Economic Affairs (originally the Central Bureau of Standards) is responsible for review and amendment. In order to strengthen the promotion on the application of the standard, the Bureau has passed on the system and Chinese character files to EDPC of Executive Yuan to manage and promote the Standard. To preserve the completeness of the Chinese character files of this system for the promotion of this national standard, the EDPC has obtained the agreement of both the Ministry of Interior and the Industrial Development Bureau, MOEA, to provide the character files for public use free of charge. Current status of CNS11643 application is as follows:
(1) Domestic Application 1. CNS11643 has been incorporated into the "Mutual regulations for information processing in governmental organizations", which is also the standards for the Chinese language processing system that most foreign Information Technology firms comply with. 2. Standard transmission codes for the exchange of electronic memorandums in governmental organizations: All governmental organizations of the Executive Yuan must covert the electronically transmitted memorandums into CNS11643 codes so long as the memorandums are transmitted via the "exchange center" (established in the Information Management Center, Ministry of Transportation). 3. Application of large-scale information system domestically: The representative example and the most important of all systems is the national Residency Information System. At the moment, the national on-line Residency Information System is built under the MITUX operating system, which is a type Client/ Server architecture. Its internal codes are ECU codes used in the UNIX operating system. Although EUC codes are different in length to that of CNS11643 codes, EUC codes use the CNS 11643 encoding architecture and character sets. Hence, this can be regarded as an example of applying CNS11643 codes as internal codes. 4. The Big-5E character set (extended Big-5 code) promoted by the Research Development and Evaluation Commission (RDEC), Executive Yuan also uses CNS11643 as its blueprint. The Big-5E character set collects 3 radical characters from CNS character plane 1, 3,891 characters from CNS character plane 3 and 59 frequently used Chinese characters in documents that are defined in CNS character plane 5. Foreign Information Technology enterprises have provided the interchange formula for conversion between the internal codes and CNS11643 code as well as calling tools to assist users in the exchange Chinese language information.
(2) Foreign Application ISO10646 and Unicode currently collect 26,783 Chinese ideographs amongst which 22,892 characters were sourced from CNS11643. They are made up by 6,307 characters from CNS11643 character planes 1,2,3, 2,965 characters from character plane 4, 395 characters from character plane 5, 196 characters from character plane 6, 133 characters from character plane 7 and 86 characters from character plane 15. The fact that our national standards are compatible with international standards, is not only going to provide domestic computer manufacturers with a competitive edge in the international market, but in future, when ISO10646 and Unicode are fully developed, Chinese character codes used currently can also be successfully interchanged.
BIG-5 Code
1. General
The Big-5 is a set of encoded Chinese characters that was developed by III (the Institute for Information Industry) on 1984. It is intended to compliant with ISO/IEC 6429 (i.e., avoid control codes) and cooperate with five commercial packages developed by Taiwan’s software houses. The Big-5 (named Big5-1984) became the industry standard for the internal code used in most Chinese computer and relative software, even it did not fully compatible with the five commercial packages. There were two versions of Big-5 derived from the original one due to different application domains, and make confuse to users. Based on the authorization from BSMI (Bureau of Standards Metrology and Inspection), the CMEX (Chinese Foundation for Digitization Technology) hold a serial of meetings to revise the Big-5 for including more useful Chinese characters on 2003. The participants of those meetings include representatives of domestic industry, experts and academics. The revised Big-5 is called Big5-2003 that includes 19,782 characters. The Big5-2003 remained the same 2-byte code scheme as the original Big5-1984, but expanded the valid value range within each bytes as shown as following:
2. Character set of Big-5
The Big-5 is a kind of internal character code consisting of 2 bytes with 19,782 code points. For the Big-5 code, the code ranges of its high byte and low byte are as follows:
| High byte | A1H ~ FEH (*126) 8EH ~ A0H 81H ~ 8DH |
|---|---|
| Low byte | 40H ~ 7EH (*157) A1H ~ FEH |
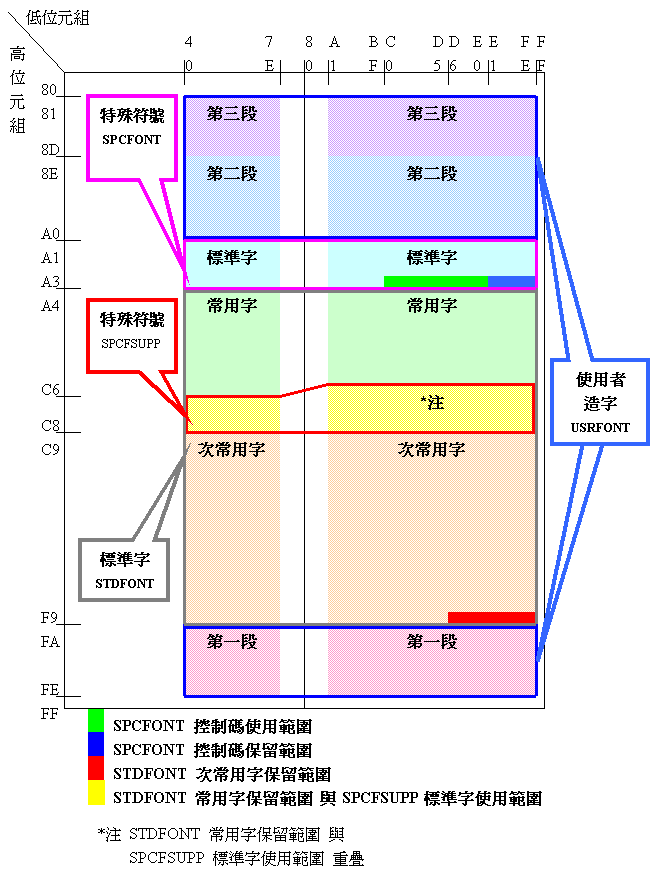
The code range of Big-5 is divided into serval areas, including Chinese character area (STDFONT), symbol area (SPCFONT and SPCFSUPP) and private use area (USRFONT), shown as follows:
☆Chinese character area(STDFONT)
| \ | Code range used | No. of characters | Code range reserved | No. of character |
|---|---|---|---|---|
| Major frequently used Chinese characters | A440~C67E | 5401 | C6A1~C8FE | 408 |
| Minor frequently used Chinese characters | C940~F9D5 | 7652 | F9D6~F9FE | 41 |
| Total | 13053 | 449 | ||
※ For the STDFONT, 兀(C94A) and 嗀(DDFC) had been removed, because of duplicating with 兀(A461) and 嗀(DCD1).
※ Totally 41 characters are included in the reserved code range of Big5-ETen and CP950.
☆ Symbol area (SPCFONT and SPCFSUPP)
1. Commonly used symbol block (SPCFONT)
| Code range used | No. of characters | Code range reserved | No. of character | |
| Symbols | A140~A3BF | 408 | --------- | --- |
| Control codes | A3C0~A3E0 | 33 | A3E1~A3FE | 30 |
| Total | 441 | 30 | ||
※ The currency symbol ERO (€) use the code point A3E1 on the reserved control code range.
2. Rarely used symbol block (SPCFSUPP)
| Code range used | No. of characters | Code range reserved | No. of character | |
| Symbols | C6A1~C8FE | 408 | --------- | --- |
| Total | 408 | 0 | ||
※ The supplemented characters of BIG5-ETen use the code points C6A1 to C8D3 on the rarely used symbol block, including Japanese Kana, Cyrillic alphabets etc.
※ The characters 〃(C6DE) and 仝(C6DF), as well as Cyrillic alphabets and special symbols with code points C7F3 to C8D3 on BIG5-ETen had been removed from BIG5-2003.
☆ Private use area (USRFONT)
| Code range used | No. of characters | Code range reserved | No. of character | |
| Block 1 | FA40~FEFE | 785 | --------- | --- |
| Block 2 | 8E40~A0FE | 2983 | --------- | --- |
| Block 3 | 8140~8DFE | 2041 | --------- | --- |
| Total | 5809 | |||
3. Comparison among various versions of BIG-5 codes
Major versions of the Big-5 used in Taiwan:
| Description | |
| BIG5-1984 | The original version developed by III. |
| BIG5-ETen | The derived version developed by ETen company. |
| CP950 | The derived version used by Microsoft. |
| BIG5-2003 | The derived version, which is based on the authorization from BSMI (Bureau of Standards Metrology and Inspection), the CMEX (Chinese Foundation for Digitization Technology) hold a serial of meetings to revise the Big-5 for including more useful Chinese characters on 2003. |
| BIG5-IBM | The derived version used by IBM. |
| Version | BIG5-2003 | BIG5-1984 | BIG5-ETen | Microsoft-CP950 | BIG5-IBM |
|---|---|---|---|---|---|
| Private use area (8140 - A0FE) | ○ | ╳ | ○ | ○ | ╳ |
| Symbol area (A140 - A2CE) | ○ | ○ | ○ | ○ | ○ |
| Full-width Latin letters (A2CF - A343) | ○ | ○ | ○ | ○ | ○ |
| Full-width Greek letters (A344 - A373) | ○ | ○ | ○ | ○ | ○ |
| Phonetic (A374 - A3BF) | ○ | ○ | ○ | ○ | ○ |
| Control symbols (A3C0 - A3E0) | ○ | ○ | ╳ | ╳ | ○ |
| Currency symbol ERO (A3E1) | ○ | ○ | ╳ | ○ | ╳ |
| Reserved (A3E2 - A3FE) | ○ | ○ | ╳ | ╳ | ╳ |
| Major frequently used Chinese characters (A440 - C67E) | ○ | ○ | ○ | ○ | ○ |
| Numeric symbol (C6A1 - C6BE) | ○ | ╳ | ○ | ○ | ○ |
| Radicals (C6BF - C6D7) | ○ | ╳ | ○ | ○ | ○ |
| Rarely used symbols (C6D8 - C6E6) | ○ | ╳ | ○ | ○ | ○ |
| Japanese Hiragana (C6E7 - C77A) | ○ | ╳ | ○ | ○ | ○ |
| Japanese katakana (C77B - C7F2) | ○ | ╳ | ○ | ○ | ○ |
| Reserved (C7F3 - C8FE) | ○ | ╳ | ○ (C7F3-C8D3) | ○ | ○* |
| Minor frequently used Chinese characters (C940 - F9D5) | ○ | ╳ | ○ | ○ | ○ |
| 7 Bif5-ETen’s supplemented Chinese characters (F9D6 - F9DC) | ○ | ╳ | ○ | ○ | ○ |
| Tabulation symbols (F9DD - F9FE) | ○ | ╳ | ○ | ○ | ○ |
| Private use area with new coming frequently used Chinese characters (FA40 - FEFE) | ○ | ╳ | ○ | ○ | ╳ |
※ Only the code points C7F3 to C878 and C8CD to C8D3 had been used.
Code range used by the BIG-5 code
Big-5E Code
1. History
The EDPC, Executive Yuan was appointed to assist with the problem experienced by many governmental organizations using the Big-5 Code that user-defined characters in electronically transmitted memorandums cannot be successfully interchanged. After several meetings of discussion, it was resolved to appoint the RDEC, Executive Yuan to set up the project "Big-5 Code Extension", to be implemented by the Chinese Foundation for Digital Technology (CMEX). In July 1997, the extension was complete and Big-5 Plus Code came into existence. However, most manufacturers have not adopted the result of this project hence related user products were unavailable. Nevertheless, the "standard character sets" completed as part of the extension plan contained the most frequently used user-defined characters in governmental documents and if applied in the user-defined area of the Big-5 Code, user-defined characters frequently used can be consolidated thus reducing the frequency of code conversion. Bearing this in mind, the RDEC, Executive Yuan once again appointed the Chinese Foundation for Digital Technology to select 3,954 characters from Big-5E and constructed the"Big-5 Extension Character Set in user-defined areas of the Big-5 Code; in line with the "e-Government Project" of the Executive Yuan, Big-5E was set as one of the codes with the ability to process Chinese characters in the exchanging of electronic official memorandums.
2. Encoding Principles of Big-5 Plus
- Length is kept at double byte. That is the first bit of high byte. (MSB=1)
- Preserve the existing architecture of "Standard character areas" and "User-defined areas" to allow for compatibility of existing systems.
- Source characters from CNS11643 and ISO10646 Chinese Ideographs Character Sets and use the encoding logic of CNS11643.
- Incorporate the character sets of ISO646 or CNS 11634 and widely used Yi-Tian user-defined characters and symbols as part of the "Standard Character Set" and keep the existing code positions.
- Any radical that is also a character by itself (such as Jien, Mu, Shuei, Huo, Tu) is not encoded again.
- The latter character of a repeated character is deleted and incorrect characters are rectified in accordance with CNS11643.
3. Source of the character set
- Source of Big-5 plus characters The internally defined character sets of Big-5 are identical to that of CNS11643 character planes 1 and 2. Thus, Big-5 Plus codes completed in July 1997 as part of the extension project also used CNS11643 as the blueprint with "standard character set" and "recommended character set" being completed. The 4,670 glyphs in the "standard character set" are frequently used Chinese characters in normal documents. Of the 4,670 glyphs, 4,145 characters were included in the CNS11643 character plane 3 and 219 characters were included in character plane 4. The 3,250 glyphs in the "recommended character set" are frequently used characters collected by manufacturers.
- Source of Big-5E characters Big-5E characters are mainly sourced from the Big-5 Plus character set. Due to the fact that there is limited space in user-defined area of the Big-5 code, the Big-5 Plus character set cannot be fully incorporated. Hence, the selection is limited to only 3,954 characters appearing in the CNS11643 character set and the ISO10646 Chinese Ideographs Character Sets that are also frequently used by governmental organizations.
4. Code Architecture
(1) Encoding Interval of Big-5 Plus Big-5 originally contains a total of 19,782 code positions. The 19,872 code positions contained in Big-5 Plus were extended to 23,940 positions (high byte: 81-FE, low byte: 40-7E, 80-FE). Description of the Big-5 Plus character set is as follows:
- Standard Character Set 1: This area is the existing the Big-5 standard character area with two repeated characters deleted and the coding interval is from A140 to F9FE (high byte- A1-F9, low byte- 40-7E, A1-FE). A total of 13,973 glyphs are collected including 5,401 frequently used Chinese characters (A440-C67E), 7,693 less frequently used Chinese characters (C940-F9D5), 471 symbols (A140-A3FE) and 408 glyphs (C6A1-C8FE)
- Standard Character Set 2: This area is the extended part; coding interval is from 8180 to FEA0 (high byte: 81-F9, low byte:0-A0) and a total of 4,158 Chinese characters are coded.
- CMEX Recommended Character Set: Due to limited code space in the Big-5 system, 3,454 characters including frequently used rare characters, Chinese character variants, simplified Chinese characters and Japanese/Korean Han characters in the first and second standard character sets cannot be incorporated. It was recommended by the CMEX to collect these 3,454 characters in this area. The coding intervals are located in the existing user-defined area from 8140 to 83FE and from 8E40 to A0FE (high byte: 81-83, 8E-A0. low byte: 40-7E, A1-FE).
- User-defined area: If only the first and second standard character sets are used, there are 5,809 available user-defined code spaces. However, if the recommended character set is used at the same time, the user-defined area only has 2,355 available code spaces as the Big-5 Plus recommended character set occupies the coding intervals from 8140 to 83FE and from 8E40 to A0FE. The available coding intervals are from FA40 to FEFE (785code spaces) and from 8440 to 8DFE (1,570 code spaces).
(2) Coding Interval of Big-5E
- 8E40 - 8E42 : Coded 3 radicals from the CNS11643 character plane 1 (Defined in Yi-Tien: C6C2, C6C5, C6C6)
- 8E43 - A0FE : Coded 2,980 Chinese characters from CNS11643 character plane 3.
- 8140 - 86DF : Coded 911 Chinese characters from CNS11643 character plane 3.
- 86E0 - 875B : Coded 59 Chinese characters from CNS11643 character plane 4.
- 875C - 875C : Chinese character of "zero".
- 875D - 87EE : 128 Reserved code spaces Installation tools and data files of Big-5E Code are available from the RDEC website.
zh_HK.hkbig5
There is system-wise supporting for encoding the Chinese characters from Hong Kong Supplementary Character Set (HKSCS). HKSCS includes 4,702 Chinese characters collected by the government of Hong Kong Special Administrative Region (HKSAR) on September 1999, which was earmarked for use as a general character set for computerization in Hong Kong.
EUC code (Extended UNIX Code)
1. Code Architecture
- (Extend Unix Code,EUC)Internal codes used by the UNIX operating system.
- Code length is 4 bytes.
2. Current Status of Application
Used by Household Registration and Military Service Organizations : The length of the EUC code is 4 bytes. Thus, it is able to collect characters used for up to 70 or 80 thousand names and meets the requirements of national household registrations.
3. Relationship with CNS11643
- Although the length of this code is different to that of CNS11643, the code however adopts the coding architecture and the character set of CNS11643.
- Correspond to CNS11643: eg. CNS 12121 = EUC 8EA1A1A1h (h represents hexadecimal)
- 1st byte : 8Eh (Fixed value)
- 2nd byte : A0h + CNS character plane (eg.: the third character plane is A3h)
- 3rd byte : 80h + CNS high byte
- 4th byte : 80h + CNS low byte
- It is not required to cross-refer codes one by one when converting EUC codes into CNS11643 codes. The only requirement is to obtain the CNS character plane number ( eg "3" of A3h) in the 2nd byte of EUC codes and then re-set the high bit of the 3rd byte and 4th byte of the EUC codes to "0" (off) to cancel the Chinese and English identification code.
Chinese Character Code for Information Interchange (CCCII)
1. History
In 1979, due to USA's urgent requirement to process some data in East Asian language by computers, a conference was held at Standard University, California to plan for an automated East Asian Library and to set a standard for Chinese Interchange Code as the basis of automation. In our country at the time, a suitable set of code was not available and Japan was the only nation that provided the national standard JISC6226 code. Hence, in the absence of other standards, the USA adopted the Japanese standard. However, the number and shape of Japanese Kanji differ significantly from those of Chinese characters and are inadequate to represent Chinese characters. In addition, this act has also significantly impacted the survival of the Chinese culture in the computerized era. Hence, representatives from our nation and the Chinese American East Asian Library opposed strongly to this idea. Subsequent to heated debates, the proposal raised by Japan and the USA was temporarily negated. At the same time, our representatives also promised to put forward a set of Chinese interchange code to compare with JISC6226 in the annual meeting of the Asian Study Association in March the next year. After returning to Taiwan, the representatives reported the issue to Mr. Kuo-Ding Lee- Minister Without Portfolio, the National Science Council and the Chinese American Association. These organizations gathered a group of local Character Study specialists, Library specialists and computing experts to form the "Chinese Character Analysis Group" (CCAG) and started the work of sorting out our national characters as well as resolving technical problems encountered in the processing of Chinese language data by computers. Professor Chieng-Jyuen Hsieh led the CCAG, assisted by Professor Chung-Tao Chang. Other project participants included Professors Chien-Hao Wang, Ding-Chung Chang, Jyuen-Fu Jou, Chung-Kuei Pan, Ho Jou, Jian-Chiau Yang and Ke-Dong Huang. In the next annual meeting of the Asian Study Association, our country proposed the "Chinese Character Code for Information Interchange" (CCCII) containing a total of 4,808 characters. The architecture of CCCII was accepted but the USA requested us to extend the character set. The CCAG finished compiling the second character set in 1981, which included 17,032 Complex characters and 11,517 variants. (Refer to Volume 2 of Version 2, published in 1982, and Volume 2 of Version 3, published in 1985 for details). In 1987, the third character set was completed and published, including 20,583 Complex characters. Other than extending coding for 53,940 characters on the two occasions, the 64 x 64 and 32 x 32 machine-readable scripts were also completed. Besides, for convenient word processing on computers, the "Chinese Character Database" (CCDB) was also compiled, in which radicals, strokes and pronunciation of each word and all types of corresponding codes and input codes were listed.
2. Character Coding Principles
- Collected characters must be recognized by Character Study academics.
- Encoded in the order of radicals and stroke order.
- Using the code point to represent the relationship between Complex Chinese characters and variants: For example, Simplified Chinese characters are treated as variants by CCCII. The encoding value of Simplified Chinese characters in the first byte exceeds that of Complex Chinese characters by six, but the encoding value of these two characters in the 2nd and 3rd byte are identical. A relationship can also be established between other variants and Complex Chinese characters in terms of code points- that is, the encoding value of variants in the first byte exceeds that of Complex Chinese characters by multiples of six. This is because Complex Chinese characters occupy six character planes (one character plane consists of 94 x 94 code points); variants are placed in the subsequent character planes and are related to the corresponding Complex Chinese characters as described above.
3. Code Architecture
The CCCII is a more special type of Chinese Character Code, using 3 bytes to represent a Chinese character. Each byte takes up 94 code positions; hence the code set is consist of 830,534 code spaces in total.
4. Current Status of Application
Used by libraries domestically and overseas.
ISO10646 and Unicode Chinese Ideographs Character Set
Due to culture differences and the fact that the respective countries use different characters for numerals, different scripts and different character application styles, ever since computers were used in the processing of information, mankind faced the problem of interchanging data between different countries. Although international coding standards such as ISO 646 and ISO 2022 are available as a guideline for the respective countries to set their own internal code or national standard interchange codes, which can be also be exchanged, as mentioned previously, ESC control codes of different length can increase the difficulties of data processing. In addition, it is impossible and unnecessary for each country to code other characters in their own standard character sets. How can we process electronic messages from other countries in the new century of forever-changing Internet technology?
1. Process of defining ISO 10646
In order to resolve the difficulty of exchanging computer data between different countries, from 1984, two organizations emerged in the hope of developing a mutual encoding character set. One was the SC2/WG3 working group of Joint Technical Committee 1 (JTC1), an organization jointed formed by the ISO and the International Electrotechnical Commission (IEC). The working group proposed the draft for ISO10646 with the intension of uniting universally used character sets to form a master character set to satisfy requirements of international information exchange. The other organization was Unicode Consortium, which also attempted to adopt new concepts and architecture in the designing of Universal Code (abbreviated to Unicode). The work and direction of these two organizations started off in separate ways but eventually they were combined to form the highly regarded standard at present, ISO10646/Unicode which provides a mutual encoding standard for the representation, transmission, interchange, processing, storing, inputting and displaying of global language characters. The standard not only avoided the waste of resources, but it also met the ideal of uniting the standards for global character interchange. From the time when the ISO/IEC JTC1/SC2/WG2 working group was first established in 1986 to the time when the first part of the ISO 10646 standard "Architecture and Basic Multilingual Plane" was published, the development phase of ISO 10646 has lasted for 10 years. The process of development is summarized below:
- 1984.4 Set up of Working Group ISO/IEC JTC1/SC2/WG2
- 1987.3 Determine Encoding Architecture
- 1989.1 Published first Draft Proposal
- 1989.12 Published second Draft Proposal
- 1990.12 Published first Draft International Standard
- 1991.6 Passed a resolution in favor of 1st
- 1992.6 Passed a resolution in favor of 2nd DIS
- 1993.5 Published ISO10646-1 (Part 1)
- 1993.5 出版 ISO 10646-1 (Part I)
In the first Recommendation Draft of ISO 10646, Version 1.0, the standard was named the Multiple Octet Coded Character Set and it was explained that the encoding architecture was in the four-octet format, making up 128 Groups. Each Group contained 256 character planes and each plane provided 256 x 256 code spaces. The 32nd character plane of the 32nd group was the Basic Multilingual Plane (abbreviated to BMP). In the ISO 10646-1 version published in 1993, the standard was named the Universal Multiple-Octet Coded Character Set (abbreviated to UCS). BMP was defined in character plane 0 of group 0. Upon application, if all required character sets are in the BMP, only a two-octet encoding architecture is required, otherwise a four-octet encoding architecture is required. Combined use of these two types of encoding architecture is not allowed. That is, either a two-octet or a four-octet regular-length encoding architecture is to be used; the purpose is to avoid the pitfall of ISO 2022 of irregular-length codes. Given this condition, representatives participating in the setting of ISO 10646 standard were all trying their best to lobby for the inclusion of their national characters in the BMP; aiming to utilize the advantage that BMP only takes up four-octet and to attain higher processing efficiency by using a four-octet code than that of a four-octet architecture. Although the BMP was very important, its code spaces were limited. Hence it is crucial at the time of setting the standard to consider how to more effectively utilize these code spaces in order to process more frequently used ideographs. In the original design of the BMP, other than Western Pin-Yin characters and symbols, only Han character sets used in Japan, South Korea and China were coded. No consideration was given to Taiwan's character sets. Consequently, the government actively organized a non-official organization under the name of Taipei Computer Association (TCA) to participate in the setting of ISO 10646 standard, lobbing for inclusion of Complex Chinese characters in the BMP. Basically, all characters used in Taiwan, China, South Korea and Japan are Han characters. Based on the encoding concepts, these characters should not be coded separately as it resulted in the situation of one character being represented by multiple codes, which is contrary to the fundamental principle of ISO 10646 of "one character, one code". As a result, representatives from our country and China proposed the Han Character Set (HCS), which was supported by the USA and other representing countries. The Character Set was developed progressively and in the BMP of ISO 10646-1 announced in 1993, Han characters used in Taiwan, China, Japan and South Korea were consolidated to become the CJK Unified Ideographs and were encoded. This was a satisfactory solution for the major Asian countries that use Han characters. The BMP character set will be introduced in later paragraphs. Since ISO 10646-1 was published in 1993, although the BMP had limited space left, many nations' characters have yet to be incorporated into the plane. Ideographs users such as our country and China have many Chinese characters that have yet to be coded into this standard. Hence, up until now, ISO 10646 is still being amended and extended. However, in recent years, the close cooperation of SC2/WG2 and Unicode Consortium has sped up the pace of amendments. Up until now, close to 30 amendments and documents of technical editing were accumulated; it is indeed a stunning effort. Based on WG2's estimation, it is expected that the new version of ISO 10646 will be released in 2000. The parallel Unicode Version 3.0 will possibly be released first in the 4th quarter of 1999.
2. Overall architecture of ISO 10646 and CJK Unified Ideographs of the BMP
As mentioned previously, the encoding architecture of ISO 10646 is four-octet. It is illustrated below:
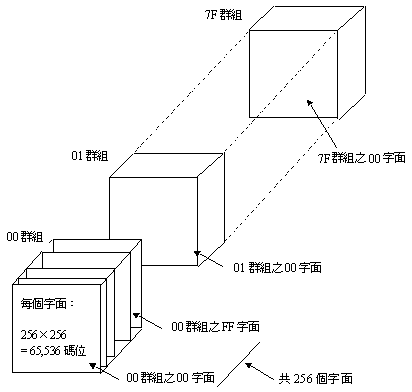
From the diagram above, it can be seen that the whole UCS code consists of 128 Groups (Group 00 - 7F) and each group contains 256 Character Planes (Plane 00 - FF); each character plane has 256 Rows (Row 00 - FF); each row consists of 256 Cells (Cell 00 -FF). Hence each character plane can accommodate 256 x 256 (total of 65,536) code spaces for character coding. The 1993 version only defined the above-mentioned fundamental architecture and characters in the BMP; there was no standard for other groups and character planes. After 1996, WG2 has set the application procedures for UTF-16 Interchange Forms, character planes other than the BMP was also defined. It is summarized below:
| Group 0 of ISO 10646 | Encoding Contents | Encoding Style |
|---|---|---|
| Plane 0(BMP) | Frequently Used Universal Character Set (include Han characters and other characters) | two-octet encoding |
| Plane 1(Supplementary Character Plane 1) | Characters other than Han characters that have not been coded | Four-octet encoding Use the UTF-16 procedure to intercept characters |
| Plane 2(Supplementary Character Plane 2) | Han characters that have not been coded | |
| Plane 3 ~ 13 | Reserved for future coding | |
| Plane 14 | Tag Characters | |
| Plane 15 ~ 16 | User-defined areas |
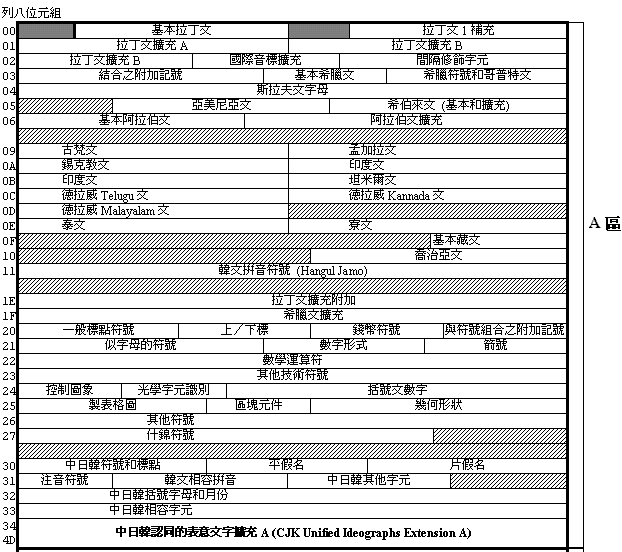
In the 1993 version, the BMP was made up by four major parts, "A", "I", "O" and "R". But it was amended to comprise of five areas "A", "I", "O", "S", and "R". Area "S" is mainly for the operation of UTF-16.
| \ | Contents | Code Position | Number of codes |
|---|---|---|---|
| Area "A" | Pin-Yin alphabets, symbols and other symbols | 0000 ~ 4DFF | 19,903 |
| Area "I" | GJK Han characters area | 4E00 ~ 9FFF | 20,992 |
| Area "O" | Reserved for future used A000 ~ D7FF | A000 ~ D7FF | 14,336 |
| Area "S" | UTF-16 operating area D800 ~ DFFF | D800 ~ DFFF | 2,048 |
| Area "R" | Private Use Area (user/ manufacturer) E000 ~ FFFD | E000 ~ FFFD | 8,192 |
Although the above zoning principles apply to coding, due to the overall consideration given to code positions and areas at the actual time of coding, the current contents of BMP differed from those described above. A typical example is the character set of "CJK Unified Ideographs Extension A", containing 6,582 characters. Due to the fact that only scattered positions were left in area "I", these characters were coded in area "A" in positions 3400 - 4DFF, which was originally intended for Hangul symbols. But since Hangul symbols were re-located to area "O", the vacated code positions accommodated the character set of "CJK Unified Ideographs Extension A". Hence, in reality, actual coding was different to that based on theory. It was required to unify CJK Han characters in area "I" because at the time of initial coding, Han characters used in the respective countries were not quite the same. For this, the SC2/WG2 invited specialists from each country forming the CJK/JRG, the former IRG to unify the entire character sets. CJK/JRG accomplished this difficult task after five meetings. References used to unify the GJK Unified Ideographs included: Character Planes 1, 2 and 14 (Column T) of the 1986 version of CNS 11643 and standard character sets from China's GB 2312、GB 12345、GB 7589、GB 17590、GB 8565(Column G), Japan's X 0208、JIS X 0212(Column J) and South Korea's KS C 5601、KSC 5667(Column K). Frequently used characters in the four regions have been incorporated. The characters were coded based on Kang-Shi Dictionary, Ta-Han-Ho Dictionary, Han Language Master Dictionary and Ta-Chi-Yuan Dictionary, in the order of radicals and then stroke order. The CJK/JRG passed the results onto SC2/WG2 for coding which completed the coding of 20,902 CJK Unified Ideographs in area I of the BMP, version ISO 10646:1993. Of the 20,902 characters coded, 17,011 characters were from the CNS 11643 character set. The CJK Unified Ideographs of BMP did not incorporate all Asian ideographs due to limited space. Consequently, it was difficult to satisfy the requirements of the respective countries. It was a consensus that the character sets of Unified Ideographs defined in BMP need to be extended. As a result, in 1993, the ISO established the Ideograph Rapporteur Group under the SC2/WG2 working group, focusing on the work of Internal / Horizontal Supplementation and External / Vertical Extension of the CJK Unified Ideographs. Participants in this project included China, Taiwan, Japan, Korea, Hong Kong, Unicode Consortium, the USA, Vietnam and Singapore. Since the establishment of the IRG, based on the custom of organizing meetings in turn and that two meetings were held each year, twelve meeting have been held to discuss the principles of extending the ideographs character sets of ISO10646's BMP and to unify and sort out characters proposed by each country. In 1998, the IRG completed the CJK Unified Ideographs Extension A, containing a total of 6,582 characters and was approved by SC2/WG2. It was planned to code these characters in 3400 - 4DFF of BMP's area A; a total of 5,879 CNS11643 characters were included. The major difference of this character set to that of CJK Unified Ideographs defined in area I was that, in addition to columns G, T, J and K, there was an additional column V to accommodate Vietnamese. Subsequent to these two stages of unification and extension of the Chinese Ideographs Sets, BMP has incorporated a sum of 27,848 ideographs. There was hardly any large space left for continuous coding. However, Chinese characters are large in number and the second supplementary character plane of ISO 10646 was planned for Chinese character extension; therefore, the extension of ideographs is still on going. The IRG's most important task at present is CJK Unified Ideographs Extension B. This character set will incorporate all characters included in Kang-Shi Dictionary, Han Language Master and national standard character sets of China, Taiwan, Korea, Vietnam and Hong Kong. The objective is to incorporate more Chinese characters into ISO 10646 to satisfy the needs of using major character sets by the respective nations. The extension used the Kang-Shi Dictionary and the Han Language Master Dictionary as the fundamental source of characters; characters that were already coded in ISO 10646 were eliminated and character sets proposed by the respective nations were added. The work was undertaken in accordance with recognized regulations. Extended B character set will be coded in Supplementary Plane 2. At present, the total number has reach some 40,000 characters amongst which included approximately 30,000 characters from character planes 4 to 7 of CNS 11643. It is expected that after the extension work is completed, 95% of the characters defined in CNS 1643 character planes 1 to 7 will be collected in the ISO 10646 standard. The remaining 5% are unified characters. This article mainly introduces Chinese related coding standards. The encoding of other ISO 10646 BMP characters cannot be introduced in detail. Readers can refer to the appendices for an understanding of the encoding details of other nation's characters in the BMP. The followings relate to ISO 10646 "Asian Ideographs users" and the CNS :
3. UCS's Encoding Representation Format and Application Procedures
Each glyph in ISO 10646 is represented by a 16-bit or 32-bit code, instead of the traditional English 1-byte code. From 0000 to FFFF (a total of 65,536 code positions); other than the positions used for control codes, 0000-001F (C0) and 007F-000A0(C1), all other spaces are available for coding. The codes can be represented by UCS-2 or UCS-4 :
- UCS-2: Two-octet BMP form. Exclusively used to represent characters or symbols in the BMP. Only uses rows and cells.
- UCS-4: Four-octet canonical form. Used to represent all characters in ISO10646. Each character is represented by a 32-bit code (group, character plane, row and cell, each occupying 8 bits)
Although the four-octet encoding format allows for very large coding space in ISO10646, its implementation requires considerable changes to the present information system. Western countries are not tending to use this format. ISO10646 has hence defined the UTF-16 (interchange format of character plane 16 of Group 00), using the 2,048 code positions in BMP area S to extend the use of character planes 1 to 16 of Group 00. The method is to divide the code positions D800 to DFFF of BMP into two areas. The upper area D800 - DBFF includes 1,024 code positions and the lower area DC00 - DFFF also has 1,024 code positions. A total of 1,048,576 (1,024 x 1,024) codes can be cross-defined and each code in this area corresponds to each code position of character planes 1 to 16 subsequent to the BMP. As such, the advantage of the two-octet format is preserved whilst using large encoding area under the four-octet format. This type of method is defined under Unicode as Surrogate. Unicode has a subdivided area accommodating 131,072 codes called the Private Use Area. The following is a comparison of the two:
| Coding Interval | ISO 10646 之UTF-16 | Unicode 2.0之Surrogate |
|---|---|---|
| D800 ~ DB7F | High-half zone | High surrogate |
| DB80 ~ DBFF | Private used high surrogate | |
| DC00 ~ DFFF | Low-half zone | Low surrogate |
From DB80 to DBFF, there are 128 x 1,024 code positions (131,072). This is the exclusive area for Surrogate. On the other hand, in order to meet the requirements of mail exchange and transmission standards of ISO 2022, control sets of 8-bit codes are avoided. ISO 10646 also defined the transformation format UTF-8, which can be used for transmitting word document data; this is required to pass sensitivity of telecommunication systems to the octet architecture and CNS 7656 control characters.
4. Future Development
Because of increasing international data exchanges and multilingual interchanges, more and more Information Technology firms have already provided or are providing more complete information processing environments based on ISO 10646. Unicode Consortium formed by several major firms has adopted ISO 10464's BMP contents as standards for Unicode and are aggressively pursuing practical application of the standard. In China, Chinese Information specialists are also aggressively pursuing practical application of ISO 10646; the impact of ISO 10646 on Chinese coding standards cannot be neglected. At the same time, the "two-shore" (between Taiwan and China) interactive relationship is changing and exchanges between the two countries are increasing. ISO 10646 can be a mutual standard for Chinese codes. Chinese Information specialist from the two countries can jointly discuss the present ISO 10646 standards to find out ways of allowing ISO 10646 to be more suitable for Chinese Information processing in the two countries, as well as to strengthen the cooperation of information technology between the two countries to improve the information processing techniques further. Appendix: Overview of the BMP of ISO 10646.

GB2312
GB 2312-80 (named Hanzi character code for information interchange – basic set) is the first national standard of information interchange code for commonly used Chinese characters in People’s Republic of China (PRC). GB 2312-80 was publish by the China National Standard Institute, and enforced by May 1, 1981.
GBK
GBK is an extension of the GB 2312-80 character set (majorly for simplified Chinese characters). In contrast to that GB 2312-80 focus on simplified Chinese characters, GBK include both traditional and simplified Chinese characters. The GBK working group accomplished the GBK specification on October 1995. GGK is compatible with GB 2312-80. It collects 70,205 Chinese characters and 883 symbols, as well as a private use area with 1,894 code points.
The telecom code
The telecom code is a Chinese character code developed by the Institute of data communication, Ministry of transportation and communication, and subject to use inside Telecommunication Company. It is an internal code consisting of 2 bytes with 17,672 code points, and divided to 2 planes. The first plane includes 7,902 Chinese characters, 41 Phonetic and 94 ASCII characters. The second plane includes 7,902 characters.